Adaptive Prior-Dependent Correction Enhanced Reinforcement Learning for Natural Language Generation
Abstract
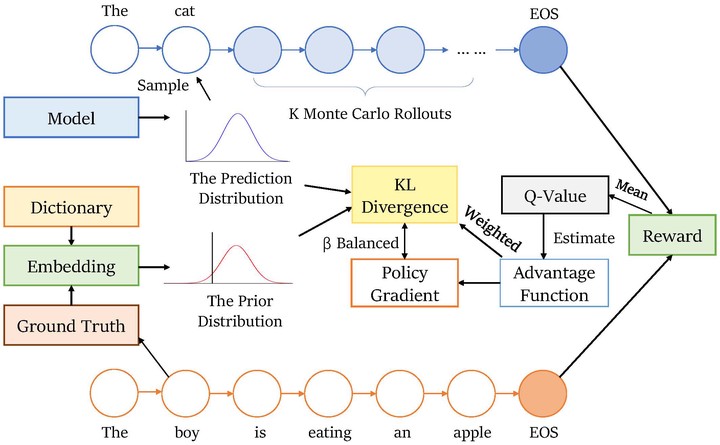
Natural language generation (NLG) is an important task with various applications like neural machine translation (NMT) and image captioning. Since deep-learning-based methods have issues of exposure bias and loss inconsistency, reinforcement learning (RL) is widely adopted in NLG tasks recently. But most RL-based methods ignore the deviation ignorance issue, which means the model fails to understand the extent of token-level deviation well. It leads to semantic incorrectness and hampers the agent to perform well. To address the issue, we propose a technique called adaptive prior-dependent correction (APDC) to enhance RL. It leverages the distribution generated by computing the distances between the ground truth and all other words to correct the agent’s stochastic policy. Additionally, some techniques on RL are explored to coordinate RL with APDC, which requires a reward estimation at every time step. We find that the RL-based NLG tasks are a special case in RL, where the state transition is deterministic and the afterstate value equals the Q-value at every time step. To utilize such prior knowledge, we estimate the advantage function with the difference of the Q-values which can be estimated by Monte Carlo rollouts. Experiments show that, on three tasks of NLG (NMT, image captioning, abstractive text summarization), our method consistently outperforms the state-of-the-art RL-based approaches on different frequently-used metrics.